Date
Apr 6, 2024
Tags
Backend
Node

In the beginning of 2024, I built Ziyo as a side project. It’s an online Kanji dictionary and search engine. It is heavily inspired by Jisho and an iOS application named Shirabe Jisho. With Ziyo, you can search across thousands of kanji and view its readings, meanings, variations, and example sentences. This makes Ziyo very useful for Japanese learner who wants to do a quick search about a kanji.


Building the search system
When I built Ziyo, I wanted Ziyo to support searching for kanji in a lot of ways. I want to be able to search by readings, meanings, etc. I also want to support searching using Korean and Chinese Mandarin reading to help people immerse into the “CJK” connection, as there are a lot of Chinese characters shared by and commonly used in China, Japan, and Korea.
So there are a lot of criteria here. Ziyo can search kanji by:
- Onyomi reading (Kana/Latin)
- Kunyomi reading (Kana/Latin)
- Chinese Mandarin reading (pinyin)
- Korean reading (Hangul/Latin)
- Meanings
This makes a pretty challenging task, as I need to search across different fields of data (by doing ”selective search”). I also want to implement some kind of weighting to better present a relevant search result, by considering the match likeness and the kanji’s popularity.
The database used by Ziyo is just a simple SQLite file containing the information above. I tried to do it in a single SQL query and it actually works according to my needs. The result is pretty satisfying.

In the example above, I search for the reading dou (どう・ドウ). It nicely ranks the result according to kanji popularity and word match. The 1st result is a common kanji for “same” and is used a lot in compound words using the meaning “same”. 2nd is “to move”. 3rd is “road” or “street”, and is also commonly used to depict Japanese martial arts/ways of life like Judo, Aikido, and even Shinto. And so on. You get the idea. As a learner, it’s probably better to learn common kanji first.
But man, is it slow
But using SQL alone is really hurting performance, as the query needed is quite large and inefficient. Although not too surprising, I didn’t expect it to be this slow. Mind you, Ziyo’s backend is a containerized Hono Node.js server in a DigitalOcean instance with 1 GB RAM and 25 GB disk space.
I tested it using a simple load test with
oha using 15 concurrent connections (the most concurrent connections I can get for it to return 100% success rate)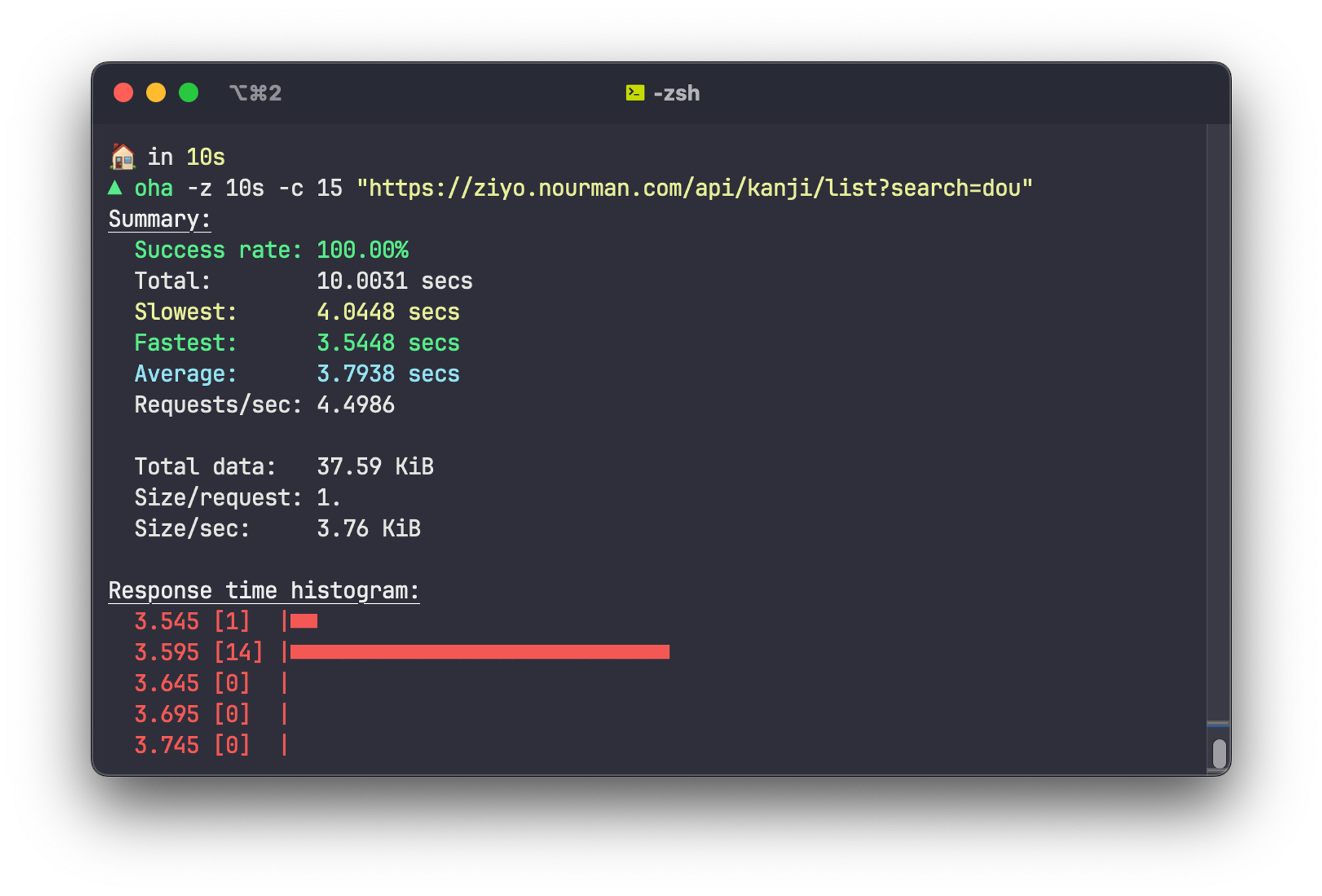
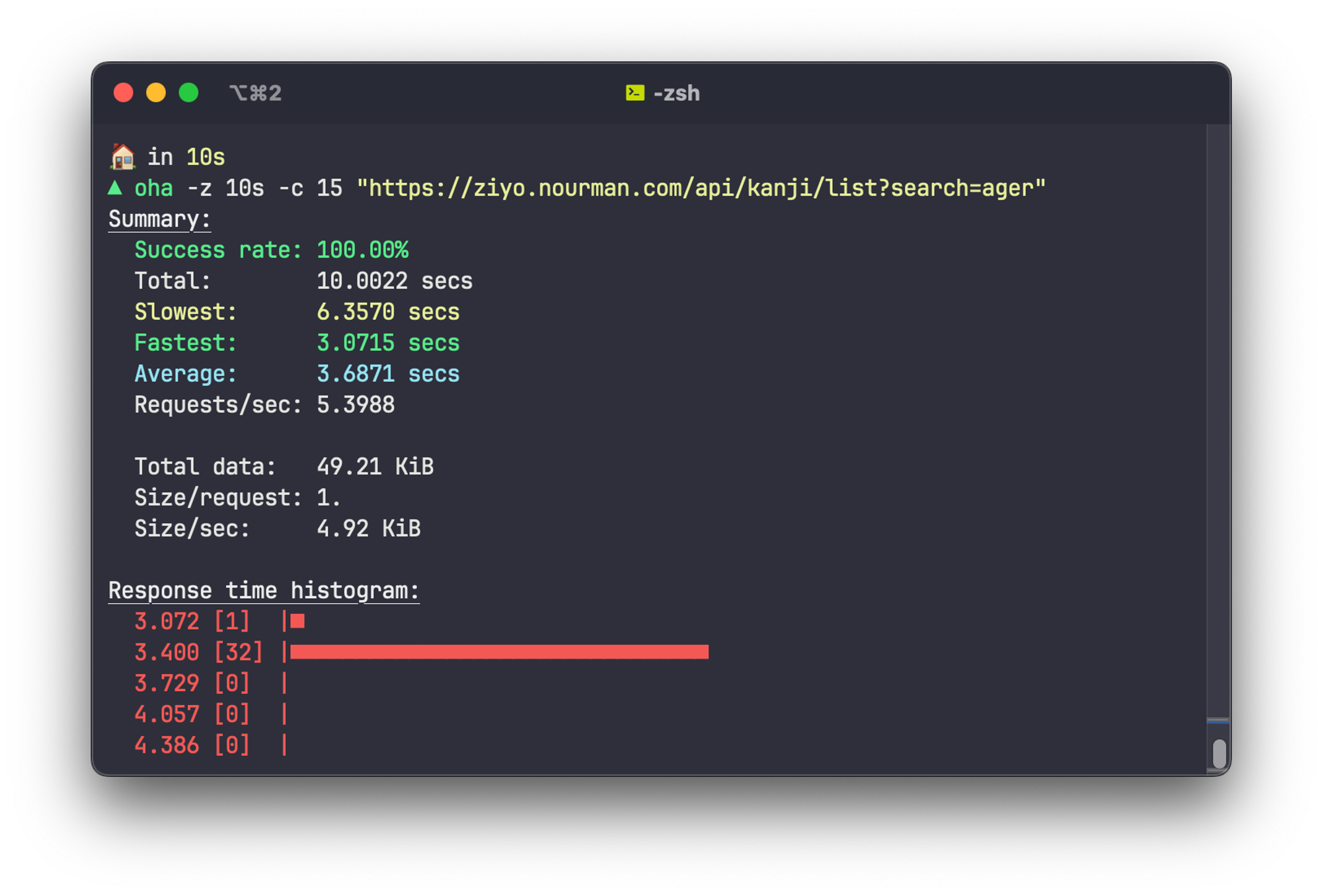
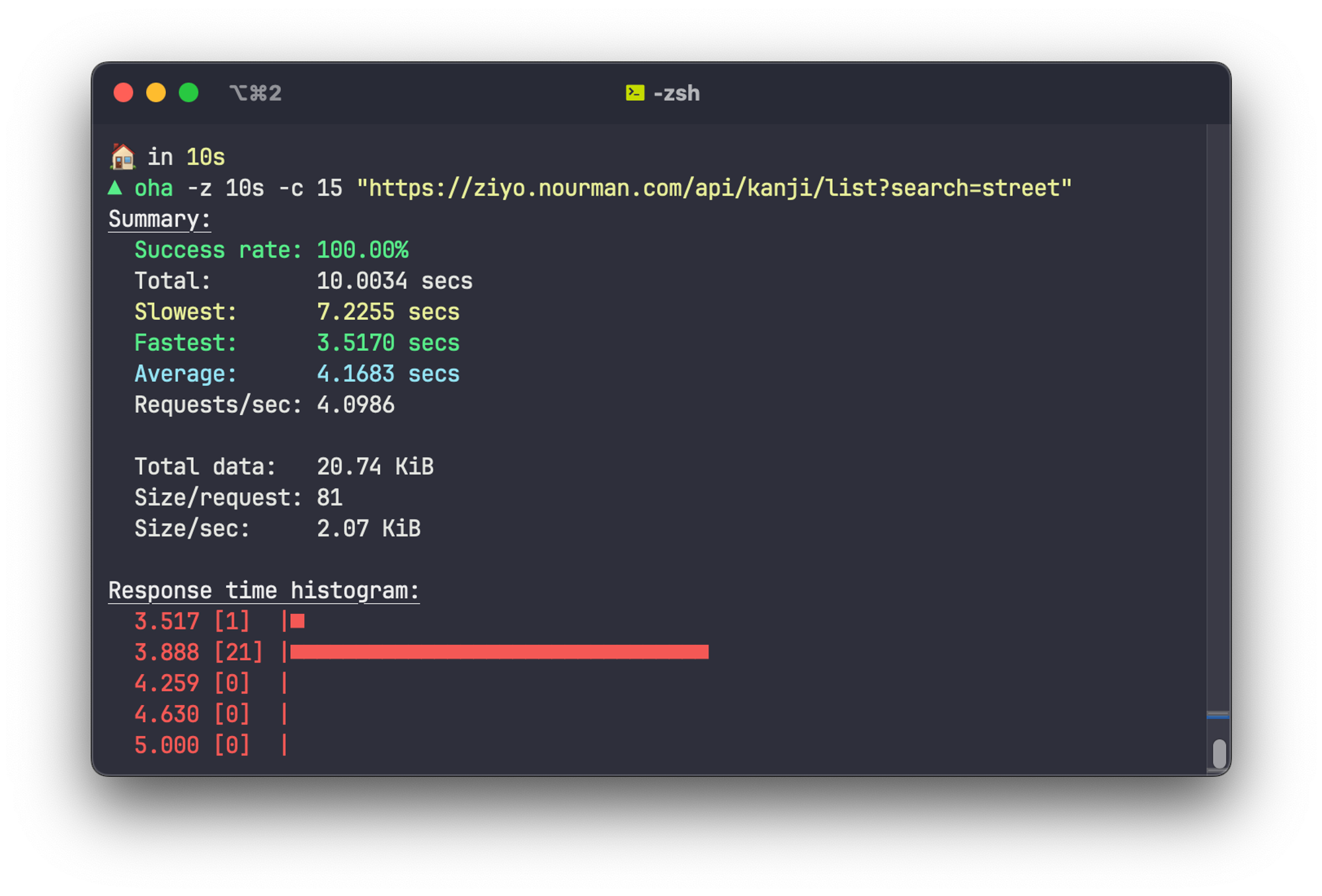
It can barely handle 3-4 RPS. We need something more powerful!
Typesense to the rescue
I haven’t been tinkering around with backend stuff for some time, so I needed research! It seems that it’s quite common for backend teams nowadays to use additional search engine like Algolia, Elasticsearch, etc, instead of implementing their own search algorithms. So I decided to try it.


I came across this post comparing Algolia, Typesense, Elasticsearch, and Meilisearch. I found Typesense to be the most powerful of them all and the easiest to set up. With some configuration, I spun a container, converted the Ziyo database into
jsonl ready to be imported by Typesense, and connected the backend code to Typesense. The result is really good.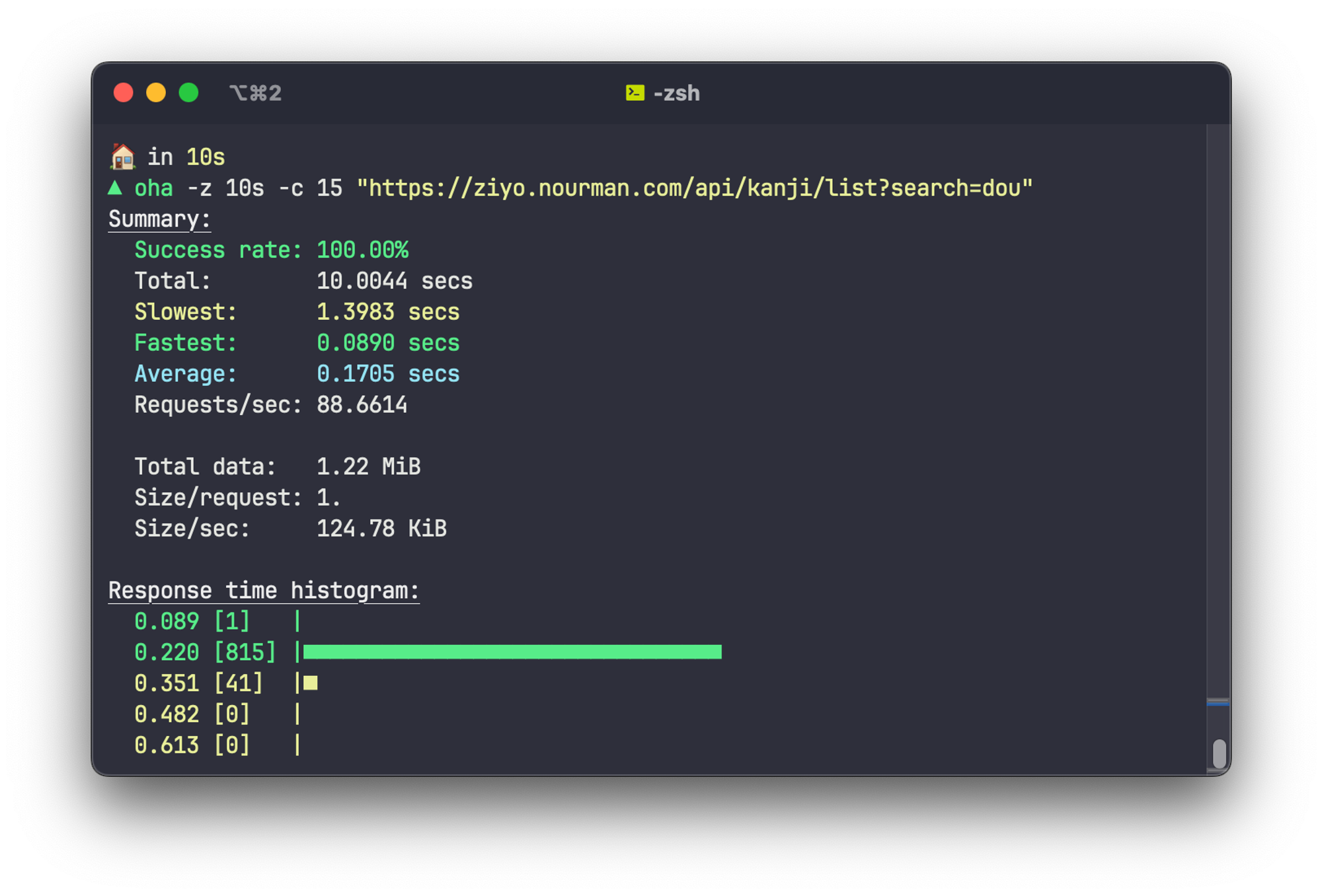
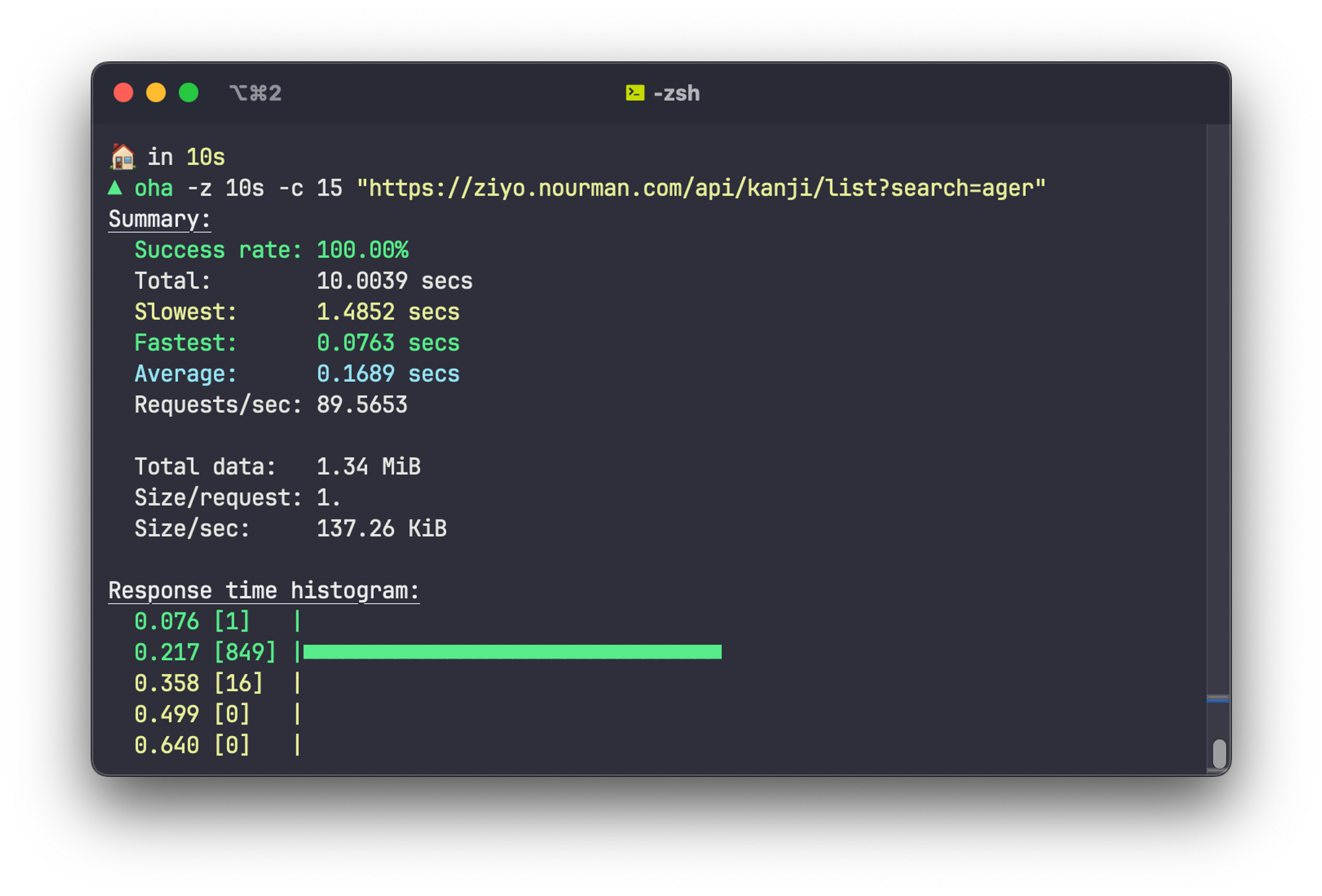
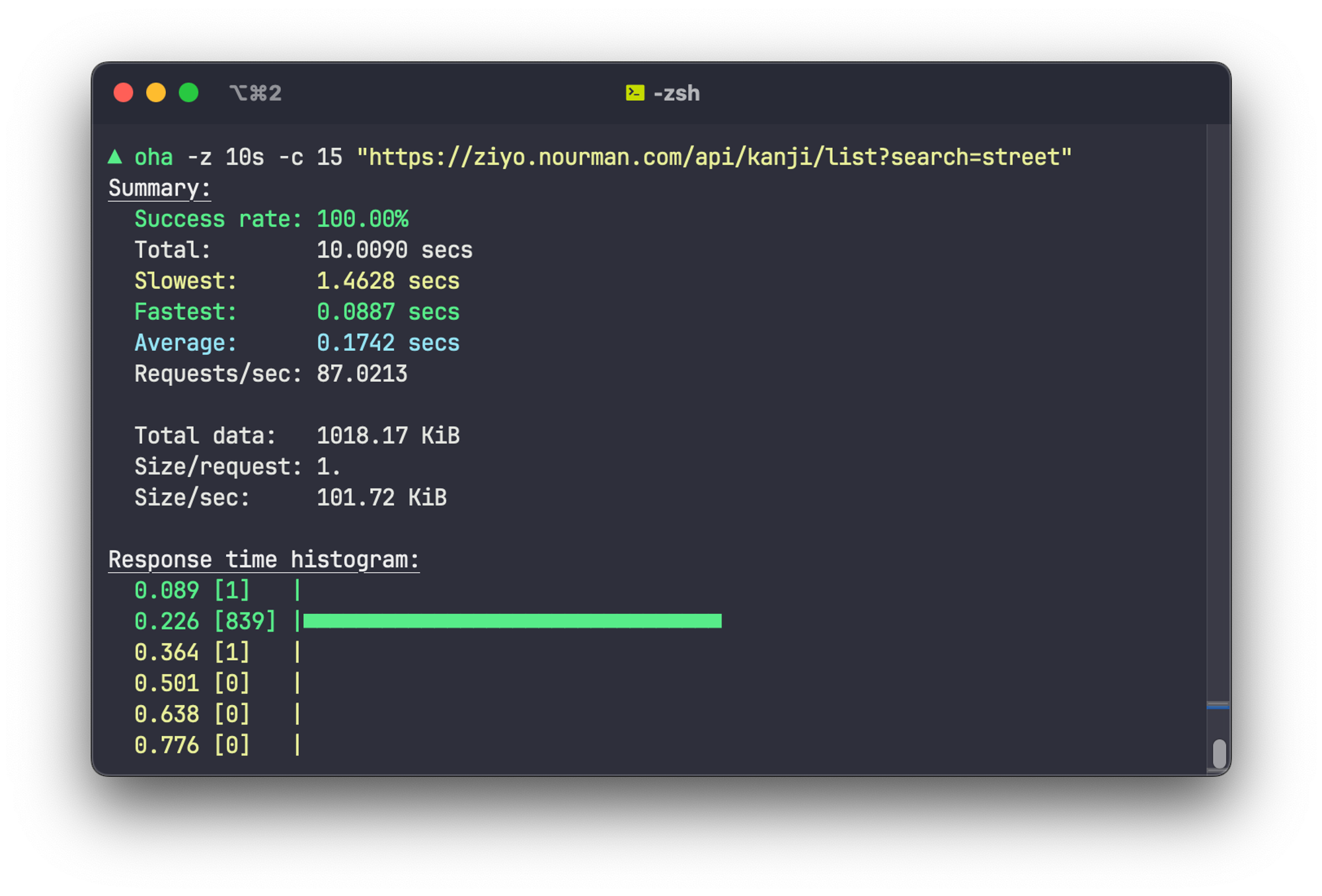
An improvement of more than 20x is achieved. It now can handle up to 89 RPS!
I’m sure I can make it faster, as I think the bottleneck is in the server capacity and my poorly optimized backend code.
Still, it is an amazing improvement. Even the search result rankings is very similar to my original code (because I used the same weights), but the performance difference is staggering.